Beaucoup d’entreprises choisissent aujourd’hui de procéder à des transformations internes selon différents objectifs : améliorer les conditions de travail des collaborateurs, faire des économies, augmenter le rendement de la production, fabriquer des produits de meilleure qualité, etc.
La méthode agile a le vent en poupe et a fait ses preuves dans divers environnements. Néanmoins, elle est généralement mise en place et appréciée dans le domaine du développement applicatif, qui permet des itérations courtes et régulières. Elle est adaptée au cycle de développement des applications. De grands groupes ont démontré qu’il était possible d’appliquer l’agilité — dont la première recommandation est de se fixer des objectifs à court terme — à des domaines où les projets au long cours sont la norme.
Le domaine de l’infrastructure est généralement en cycle en V, ou pratique ITIL, et effectue souvent une transformation vers le DevOps (qui n’est pas une méthode, mais plutôt un ensemble de bonnes pratiques, comme le pair programming ou eXtreme Programming/XP).
Nous avons eu la chance de mener une transformation agile au sein d’un pôle Infrastructure en pleine restructuration. C’est donc en tant que Product Owner (PO) et Scrum Master (SM), responsables entre autres de la construction de la DMZ (demilitarized zone) pour un client dans l’énergie, que nous présentons la méthode agile appliquée par notre équipe.
L’objectif de ces lignes n’est pas de vous former à l’agilité, mais de partager un retour d’expérience, des ressentis, des idées pour mener ce type de projet, ainsi que des points d’attention utiles pour vos futures missions.
Organisation interne
Un grand client du secteur de l’énergie dispose d’un pôle Infrastructure à restructurer à la suite d’une scission interne. Le client doit devenir autonome sur son infrastructure et architecturer l’ensemble des éléments nécessaires au bon fonctionnement de tout son parc applicatif, ainsi que sa propre connexion à Internet, avec un niveau de sécurité très élevé.
Le management de la DSI a décidé de mettre en place l’agilité au sein d’un plateau d’environ 200 personnes qui travaillaient jusque-là en ITIL ou en cycle en V. L’arrivée de coachs agiles a permis d’installer les bases de SAFe et de Scrum/Kanban au sein des équipes.
L’organisation comprend :
6 socles composés de plusieurs trains (9 trains dans le socle infrastructure de traitement). Le train Infrastructure est lui-même composé de 22 équipes, regroupées en 4 lignes produits. Ces équipes comprennent de 5 à 10 équipiers, avec obligatoirement 1 SM et 1 PO par équipe.
Un train unique, organisé en 4 lignes produits et piloté chacune par un Product Manager (PM), permet de lier l’ensemble des équipes et de traiter les nombreux sujets transverses.
Le RTE et son équipe, constituée principalement de coachs agiles, s’assurent du respect de la méthode, de la tenue des cérémonies au niveau du train (Program Increment (PI) Planning, démonstrations, etc.), de la circulation des informations auprès des PM et, surtout, de l’efficacité de la communication transverse entre les lignes produits.
Les SM, au-delà de faire respecter la méthode au sein des équipes, jouent un rôle d’alerte lorsqu’un sujet est transverse et peut impacter d’autres équipes.
Rappel, contexte et solution
Le sprint vient souvent à l’esprit quand on parle d’agilité. D’une durée de 2 à 3 semaines, il permet d’incrémenter les fonctionnalités de manière successive et d’obtenir un retour des parties prenantes après chaque livraison… livraisons qui doivent être réalisées dans ce délai de 2 à 3 semaines.
Le sprint n’est pas la méthode agile : c’est simplement un des outils (une cérémonie, pour être exact) mis à disposition pour développer et/ou maintenir un produit.
Dans la théorie, le Manifeste agile s’articule autour de 4 valeurs et 12 principes, mis en œuvre au travers du trio : Product Owner (PO) / Scrum Master (SM) / équipiers (dans notre cas, des experts réseaux).
En lisant le Manifeste, on perçoit les contradictions soulevées par l’agilité appliquée à des chantiers d’infrastructure, par exemple :
Concernant le Product Owner, il peut être présenté comme un chef de projet agile (ce que laissent parfois entendre certaines offres). Dans un premier temps, il est tentant de se raccrocher à ce que l’on maîtrise (chef de projet ou pilote de service pour du RUN).
Pourtant, la différence majeure tient au terme « responsable produit ». L’idée est simple : accélérer la réactivité, la prise de décision, et en finir avec les attentes de trois semaines et le prochain COPIL pour savoir si l’on part sur telle ou telle solution. L’une des tâches principales du PO est d’échanger en continu avec l’ensemble des parties prenantes (métier/client, technical leader, architecte, etc.) afin de rester au plus proche de l’attendu et d’anticiper risques et évolutions.
D’autres tâches incombent bien sûr au PO (rédaction des User Stories, suivi du backlog, etc.), ainsi que des missions spécifiques à l’entreprise (administration et gestion de l’équipe, recrutement, par exemple).
Au final, on comprend que cette méthode est axée sur l’accélération du temps :
pour développer ;
pour modifier ou corriger ;
pour décider.
Question : comment associer temporalité courte et chantiers longs, où les risques de dérive sont intrinsèques aux projets d’infrastructure ?
Montée à l’échelle (SAFe), Program Increment et Kanban
En tant que PO, il est difficile d’imaginer piloter un chantier d’infrastructure réseaux et télécom sans tenir compte des contradictions précédentes. Cependant, l’agilité est permissive et offre un panel d’outils permettant d’établir une feuille de route sur plusieurs trimestres : la montée à l’échelle via SAFe (Scaled Agile Framework).
SAFe permet, à l’aide de son framework, de définir une stratégie et une vision à moyen terme. Évidemment, ce framework est adapté au contexte de l’entreprise. En infrastructure, on sait généralement ce que l’on veut et comment (mise en place d’un cœur de réseau, déploiement d’un réseau Wi-Fi, etc.). L’idée est de « découper » le chantier en fonctionnalités comme on le ferait dans un jalonnement « standard » (A, B, C, etc.), puis de rédiger, à l’attention de l’équipe, les User Stories (US) permettant de réaliser ces fonctionnalités.
Cette découpe est rendue possible par l’intégration des Program Increments (PI) de SAFe, qui offrent une approche structurée pour développer l’agilité à grande échelle en synchronisant plusieurs équipes. Dans le cas présent, nous évoquons un projet d’infrastructure porté par une seule équipe, mais SAFe est conçu pour les grandes organisations (département, entreprise) et regroupe plusieurs équipes agiles via un train, comme présenté précédemment.
En résumé, les PI sont utilisés pour découper le projet d’infrastructure et réaliser une roadmap.
Program Increment (PI) et fonctionnalités
D’une durée d’un trimestre dans notre exemple, un PI débute par un PI Planning de deux jours durant lequel on planifie l’ensemble du travail à réaliser, et se termine par trois sessions de démonstration (ou revues de fonctionnalités) pour valider ce qui a été accompli et informer l’ensemble du train des avancées, avant de recommencer le cycle.
Ainsi, dans chaque PI, nous découpons notre chantier en fonctionnalités et proposons une première vision macro du trimestre à venir. Les fonctionnalités sont estimées, priorisées et alimentent le backlog produit.
NB 1 : nous savons qu’un PI est censé durer de 8 à 12 semaines et qu’un train doit compter entre 50 et 125 personnes. Notre train regroupe 250 personnes sur des périodes de 13 semaines : c’est une contrainte d’entreprise avec laquelle nous devons composer.
NB 2 : en agile, la notion de temps de réalisation est proscrite ; on parle plutôt de capacité à faire d’une équipe. Vos clients demanderont néanmoins une date de livraison. La capacité à faire est un travail statistique réalisé par le Scrum Master, qui permet de déterminer la charge possible et d’éviter la surcharge ou la non-réalisation. Il utilise également la vélocité pour estimer au mieux la charge de l’équipe.
Durant le PI, vous pouvez encapsuler des sprints comme le suggère Scrum. Néanmoins, le sprint est efficace pour une équipe réellement autonome sur des fonctionnalités « courtes », mais il est moins permissif vis-à-vis des aléas externes et des phases d’étude. Nous avons donc opté pour Kanban, plus adapté et préféré par les équipes, qui subissent moins la pression du timeboxing de 2 ou 3 semaines.
Retour d’expérience – Product Owner
Comme précisé en introduction, ce billet présente une méthode fonctionnelle dans un contexte particulier ; il existe sûrement d’autres variantes plus adaptées à la gestion d’un projet d’infrastructure en agile.
Quoi qu’il en soit, voici nos remarques et limites observées sur le terrain.
User Story (US) et Kanban
Généralement, les US sont rédigées par le PO : elles doivent décrire une fonctionnalité du point de vue de l’utilisateur, en langage non technique, selon le formalisme :
« En tant que [profil client], je souhaite [objectif du produit] afin de [résultat]. »
Deux problématiques majeures apparaissent :
le PO ne peut pas être au même niveau technique que les équipiers (experts) ;
le formalisme « utilisateur » est parfois éloigné de la réalité (ex. : « configurer des clusters de FW » ou « câblage du matériel »).
Dans notre cas, nous utilisons une Definition of Ready (DoR) sur le triptyque Contexte / Quoi / Pourquoi en description de la fonctionnalité. Cela suffit amplement pour permettre à l’équipe de demander des précisions et susciter la discussion en cas d’incompréhension.
En Definition of Done (DoD), nous avons des critères d’acceptation fixés par le PM.
L’équipe rédige le titre des US, utilisées comme tâches à réaliser. Cela offre de la souplesse sur plusieurs lignes produits pour les équipes transverses comme la nôtre.
NB : les chefs de projet le savent, un projet qui dérive, c’est normal ; un projet à l’arrêt, c’est souvent mauvais signe. Il est donc impératif de découper une fonctionnalité en un maximum d’US, car certaines peuvent se retrouver « en attente » pour des raisons externes (retard de livraison, par exemple). Multiplier les US permet de basculer sur une autre tâche réalisable en parallèle. Une fonctionnalité peut être déterminante pour lancer la suivante (dépendances), à l’inverse des US, souvent indépendantes.
Au travers du tableau Kanban, constitué de 3 ou 4 colonnes (« À faire », « En cours », « Terminé »), le PO peut prioriser, assigner et suivre l’évolution des US de toutes les fonctionnalités attachées à l’équipe. Dans notre contexte, nous suivons aussi plusieurs lignes produits (ZNET, VPA, DMZ, etc.).
Revue de backlog & préparation du PI Planning
Parmi les rituels, le plus connu est le Daily, quotidien, court (15 minutes maximum ; s’il dure 5 minutes, ce n’est pas grave) et animé par les équipiers, qui échangent sur leur travail en cours et les difficultés rencontrées. Attention : ce n’est pas un compte rendu journalier au PO (qui, comme un chef de projet, n’est pas un manager). Le PO peut être présent ou non, demander ou donner des informations.
La revue de backlog (Product Backlog Refinement) est hebdomadaire (1 heure), animée par le PO : elle permet de passer en revue l’ensemble des US, de valider celles qui sont terminées et de clarifier celles qui passent en réalisation.
Le PI Planning, enfin, débute chaque nouveau PI. D’une durée de 2 jours, c’est probablement la cérémonie la plus importante de SAFe : il aligne l’ensemble des équipes (gestion des dépendances) et c’est durant celui-ci que nous validons le backlog du PI à venir. Ce rituel étant dense, nous le préparons par 2 à 3 réunions, afin d’avoir une vision précise du backlog et de simplifier la gestion des dépendances.
NB : les difficultés doivent être remontées rapidement au PO. Il lui appartient de débloquer la situation en sollicitant Technical Leaders, architectes, achats (en cas de retard de livraison), autres équipes via leurs PO, etc.
Concernant les US non terminées dans le temps imparti : prenons un cas entre deux PI (3e et 4e trimestres). Si vous rencontrez des problèmes de câblage lors de l’intégration des équipements et que l’US « Câblage du matériel » n’est pas terminée, la découpe étant bien faite, l’équipe a pu terminer la majorité des autres US et valider la plupart des critères d’acceptation. Vous vous retrouvez alors dans l’impossibilité de valider la fonctionnalité alors qu’elle est réalisée à 95 %, les 5 % restants ne dépendant pas de l’équipe. Frustrant ! Un partenaire externe empêche la clôture. Conséquence : l’ensemble de la feature n’est pas comptabilisé comme terminé pour la clôture du PI.
Plusieurs options :
Décaler la fonctionnalité entière sur le PI suivant, en supposant une dérive minime et une clôture en début de PI.
Décaler la fonctionnalité, mais estimer que la charge supplémentaire impactera le plan initial, et rescoper la fonctionnalité suivante.
Transférer l’US restante dans la fonctionnalité suivante afin de valider celle en cours. Cette option nécessite de revoir le scope de la fonctionnalité en cours pour la clôturer (adapter les critères d’acceptation avec le PM).
Ce travail se fait avec le SM (capacité à faire de l’équipe) et avec le PM (modifications de scope des fonctionnalités), afin d’expliquer pourquoi vous affichez un « faux » retard.
NB du SM : nous sommes conscients que modifier le scope en cours de PI est une hérésie pour les évangélistes de l’agilité. Néanmoins, quand 3 mois de travail de 2 ou 3 personnes sont « invalidés » dans les statistiques du train à cause d’un document de validation externe manquant, cela fausse la vélocité d’équipe.
De notre point de vue (et après avoir testé les trois), la troisième solution est souvent appliquée, notamment pour des raisons humaines et de bien-être de l’équipe :
Frustration évitée lorsque la non-clôture ne dépend pas d’elle.
Maintien d’une dynamique d’avancement, évitant l’impression de stagnation.
Remise en question utile de notre rôle de PO/SM : capacité à faire, découpage en US, anticipation des risques.
NB (SM) : une option plus « propre » est de découper plus finement les fonctionnalités, sous forme de lots. Cela permet de conserver la visibilité sur la charge réalisée, de visualiser le reste à faire non réalisé et de le faire glisser sur une nouvelle fonctionnalité.
Documentation et reprise en exploitation
L’une des 4 valeurs de l’agilité est « le produit opérationnel plus que la documentation exhaustive ». Il est donc tentant de minimiser la documentation.
Mais en tant que responsable produit, vous ne devez pas vous limiter à la valeur client : en infrastructure, ce que vous construisez sera ensuite exploité, souvent par une autre équipe, entité ou entreprise (NOC, service desk, etc.).
Dans SAFe, le « client » est généralement représenté par le Product Manager (PM), qui, avec l’aide de Technical Leaders (TL) ou d’architectes, transforme les besoins métiers en fonctionnalités techniques à réaliser par les équipes agiles. Il est donc votre contact privilégié (votre N+1 opérationnel, et parfois votre client si vous êtes prestataire).
Dès qu’un produit est opérationnel, le PM vous soumettra un nouveau besoin… mais en tant que PO, vous restez responsable jusqu’à la mise en exploitation. Même si cela ne représente pas une valeur directe pour le client, certaines tâches sont indispensables avant la production (recette, validation cybersécurité, etc.). Vous devrez rappeler et quantifier ces tâches avec l’aide du SM, car elles représentent un travail non négligeable pour l’équipe.
Il est nécessaire de créer des US de documentation tout au long du projet (DAT, DEX, recette, par exemple) afin d’organiser le transfert de compétences et la reprise en exploitation par un autre service (comme le NOC).
Par ailleurs, le turn-over élevé dans nos structures impose de maintenir la documentation pour éviter la perte de connaissances et faciliter les passations.
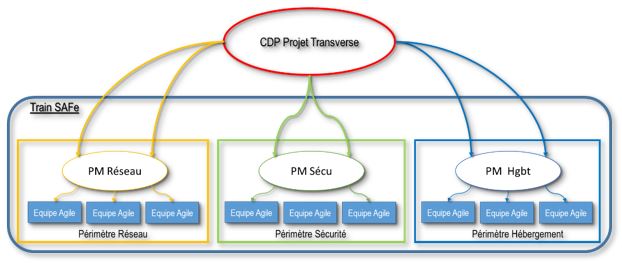
Projet transverse
Par analogie, sur un navire, il n’y a qu’un seul capitaine responsable de la direction. De même, le pilotage d’un projet doit être porté par une personne ou entité unique.
Dans un train SAFe, si un projet transverse se présente, il faut d’abord qu’un PO référent se propose comme responsable du produit (en plus de son périmètre), puis qu’il négocie avec les autres PO pour prioriser les besoins de chacun en tenant compte des charges et du staffing de chaque équipe — sachant que les PM sont différents… Cela devient vite une dépense d’énergie considérable pour un résultat limité.
Selon nous, un CDP/PO/PMO ou une entité au-dessus des PM aura plus de facilité à faire avancer un projet transverse en mobilisant les compétences disponibles dans le train agile.
Retour d’expérience – Coach agile
Dans un premier temps, il a fallu former les équipes aux nouveaux outils de gestion agile (Go Jira dans notre cas). Des formations aux bonnes pratiques et aux objectifs de l’agilité ont été rendues obligatoires. Les SM ont pour mission d’accompagner progressivement la migration, selon la maturité de leurs équipes et des personnes qui les composent.
La première étape est l’acceptation des cérémonies. Les SM ont des approches variées (jeux sérieux, échanges, etc.). Le choix a été de laisser l’initiative aux SM selon leurs équipes ; pas d’uniformisation immédiate des processus. Dans un second temps, les SM ont fixé un cadre plutôt Scrum ou plutôt Kanban selon la typologie d’équipe.
Des lignes guides rédigées par les coachs agiles ont permis d’uniformiser certains points (rôles et actions communes : digit dashboards/« météo projet » sur les features principales à la charge des SM, validation finale des features par les PM, harmonisation des Definition of Ready et Definition of Done, etc.). Néanmoins, le contexte infra implique de laisser certaines libertés à chaque équipe.
Le framework agile adapté à l’infrastructure a été mis en place avec une grande part de liberté et de souplesse. Il faut toutefois rappeler les spécificités du domaine qui complexifient cette mise en œuvre.
Nous relevons au moins quatre particularités majeures :
Des équipes aux compétences très diverses
Au sein d’une même équipe, certains font de l’installation de matériel (contraintes d’approvisionnement et d’installation), d’autres développent des configurations serveurs, d’autres gèrent la sauvegarde de données ou les portails d’accès aux applications.
Les contraintes sont donc très différentes ; quand certains pourraient travailler en sprints de 2 semaines, d’autres ne le peuvent pas (ex. : délais de livraison matériels).
La gestion du matériel (hardware)
Les délais de livraison peuvent varier de 1 à 6 mois, sans levier de maîtrise. En conséquence, des sprints de 2 à 3 semaines sont inapplicables pour ceux qui gèrent l’installation en datacenter. Les informations d’installation étant délocalisées, il est difficile (voire impossible) d’obtenir des dates précises. Même en découpant au plus fin, la moindre tâche met rarement moins de 2 à 3 semaines à se résoudre.
De fait, une méthodologie Scrum avec sprints paraît difficilement applicable au sein de ces équipes, qui souvent ne la souhaitent pas.
L’interdépendance forte entre équipes et prestataires externes
Le nombre de prestataires externes est très élevé, et le client n’a pas toujours de moyens de gestion/priorisation vis-à-vis d’eux (contrats). Malgré la mise en place des PI (3 mois), chaque PM gère un domaine (ligne produit) avec ses propres contraintes et priorités. Les équipes métiers diffèrent, avec des attentes parfois contradictoires (connexion Internet rapide vs hébergement applicatif prioritaire). Les PM ont une forte responsabilité de priorisation.
Les équipes sont souvent frustrées et dépendantes d’urgences/priorités extérieures à leur ligne produit. Les tâches engagées comportent une forte incertitude quant à leur complétion sur 3 mois. Cela nécessite un management rassurant et une protection forte des SM, pour éviter d’imputer aux équipes des retards qu’elles ne maîtrisent pas.
Dans ce contexte, le train étant surdimensionné, il existe une tendance à surcharger les PI de fonctionnalités par manque de visibilité sur les priorités des autres lignes. Pour les SM, il est primordial d’obtenir rapidement une vélocité d’équipe afin de s’engager uniquement sur une charge réaliste et de limiter cette surcharge.
La typologie humaine des collaborateurs en infrastructure
Sans généraliser, on est loin du stéréotype de la start-up : on parle de personnes expérimentées, sur des technologies complexes, souvent peu enclines au changement organisationnel. Le frein humain est réel, et l’accompagnement des SM est d’autant plus délicat.
Ces collaborateurs ont le sens des procédures ; l’agilité souffre parfois d’une image négative (souplesse, objectifs mouvants). Il faut beaucoup d’accompagnement et de pédagogie. Les SM doivent veiller à la stabilité des processus. Nous recommandons un SM expérimenté dédié à chaque équipe plutôt qu’un équipier jouant aussi le rôle de SM.
Les tâches d’infrastructure laissent peu de place à l’exploration : des canevas et « bonnes pratiques » s’imposent ; beaucoup de travail exécutif sur plusieurs semaines.
Points forts de l’agilité en infrastructure
Des équipes clairement distinctes qui peuvent atteindre l’autonomie à mesure que leur maturité agile progresse.
Un cadre rassurant et protecteur : fin de la culpabilisation en cas de retards qui ne relèvent pas des équipes ; baisse des demandes « impromptues » dues aux changements de priorité.
Assainissement du cadre de travail : l’agilité rend visibles les problèmes que l’on ne voulait pas voir ; ils peuvent être identifiés et traités.
Plus de visibilité sur l’ensemble des sujets et sur la capacité réelle des équipes, souvent surestimée ; les dépendances et interconnexions sont mises en avant.
En tant que coachs agiles, nous savons que l’agilité porte une philosophie au-delà des règles et cérémonies qui la structurent. Elle est adaptable à tous les environnements, pour peu qu’elle soit appliquée intelligemment. Soyons clairs : SAFe, Scrum, Kanban « by the book » ne sont pas applicables en l’état. En revanche, SAFe est pertinent avec un train dimensionné (pas plus de 70–80 personnes), Kanban, les backlogs et les tableaux de suivi sont parfaitement applicables, et l’ensemble des cérémonies le sont aussi lorsqu’elles sont amenées avec tact.
Conclusion
Faire cohabiter méthode agile et projets d’infrastructure réseaux & télécom est possible !
L’agilité est permissive : des courants (Lean) et des frameworks (SAFe) servent de points d’appui pour l’adapter aux besoins. Elle est efficace lorsqu’elle est appliquée avec intelligence, souplesse et adéquation au contexte. Il existe toutefois un dimensionnement à respecter pour qu’elle révèle toute son efficacité.
Cette souplesse ne signifie pas que tout est possible : l’accompagnement par des coachs agiles et des Scrum Masters est nécessaire pour éviter de trop s’éloigner du Manifeste… ou, à l’inverse, de vouloir le respecter au pied de la lettre. Il est important de recruter des personnes expérimentées ; nous déconseillons des profils trop juniors, pour qui l’expérience peut être désagréable ou démotivante au regard des contraintes inhérentes à l’infrastructure.
En tenant compte de ces retours, il nous revient à tous de tester, d’évaluer nos erreurs et d’améliorer la méthode afin de produire plus vite de la valeur et de réduire le gâchis. L’objectif est de conserver l’esprit de l’agilité tout en tenant compte des contextes et contraintes des entreprises.